

Getting stock volatility in R & Getting Histogram of returns
[Risk return relationship in 2015]
According to the CAPM theory, there is a linear relationship between the risk inherent in the stock and the return. It makes sense. It's consistent with the Golden Rule "Low risk low return, High risk high return"
However, that was not the case in 2015. I don't know why. Maybe I have to ask it to finance professors to figure out what was going on and what made them being deviate from the theory.
[Before getting into code]
I had to use a lot of packages. Thus, those who do not install following packages, please install them first. Just like other packages, it's free. I used string manipulation a little bit. It could be harder for those who are not familiar with regular expression. I'll post it later. Please bear with me.
TTR, plyr, tseries, stringr, calibrate
You can install with "install.packages()" command in your R.
[R Code]
#Getting TOP 100 stocks in NYSE volatility and return
library(TTR) #To get tickers
library(plyr) #For sorting
library(tseries) #For volatility / return
library(stringr) #String manipulation
library(calibrate) #To represent stock name on scatter plot
#NASDAQ, NYSE
market <- "NYSE"
#Technology, Finance, Energy, Consumer Services, Transportation, Capital Goods, Health Care, Basic Industries
sector <- "Finance"
getcapm <- function(stock) {
#Getting data from server
data <- get.hist.quote(stock, #Tick mark
start="2015-01-01", #Start date YYYY-MM-DD
end="2015-12-31" #End date YYYY-MM-DD
)
#We only take into account "Closing price", the price when the market closes
yesterdayprice <- data$Close
#This is a unique feature of R better than Excel
#I need to calculate everyday return
#The stock return is defined as (today price - yesterday price)/today price
todayprice <- lag(yesterdayprice)
#ret <- log(lag(price)) - log(price)
rets <- (todayprice - yesterdayprice)/todayprice
#Annualized and percentage
vol <- sd(rets) * sqrt(length(todayprice))
geometric_mean_return_prep <- rets + 1
geometric_mean_return_prep <- data.frame(Date=time(geometric_mean_return_prep), geometric_mean_return_prep, check.names=FALSE, row.names=NULL)
#geometric_mean_return <- exp(mean(log(geometric_mean_return_prep)))
geometric_mean_return = 1
for(i in 1:length(geometric_mean_return_prep)) {
geometric_mean_return = geometric_mean_return * geometric_mean_return_prep[i,2]
}
geometric_mean_return <- geometric_mean_return^(1/length(geometric_mean_return_prep))
geometric_mean_return <- geometric_mean_return -1
information <- c(geometric_mean_return, vol)
return(information)
}
convert_marketcap <- function(str) {
str <- gsub("\\$", "", str) #Get rid of "$" first
#The reason why I use \\ is that $ has a special meaning in regular expression
#Regular expression is not the topic. #I'll deal with later
multiplier <- str_sub(str,-1,-1) #Million? Billion?
pure_number <- as.numeric(gsub("(B|M)", "", str)) #Get rid of M or B. Turn it into number
if(multiplier == "B") {
#Billion
adjustment <- 1000000000
} else if(multiplier == "M") {
#Million
adjustment <- 1000000
} else {
#Don't adjust it.
adjustment <- 1
}
return (pure_number * adjustment)
}
original <- stockSymbols()
#Getting NASDAQ
listings <- original[original$Exchange==market,]
#As these data include "NA," we need to clean them up for further data manipulation.
#If you don't clean up NA, you would encounter error while manipulating
listings <- listings[!is.na(listings$MarketCap),]
listings <- listings[!is.na(listings$Sector),]
#I want to focus on the specific sector
listings <- listings[listings$Sector==sector,]
#Market cap is string right now. We need to convert this to number
listings$MarketCap <- sapply(listings$MarketCap, convert_marketcap)
#Sort the list descending order of market capital
listings <- arrange(listings, desc(listings$MarketCap))
capm <- data.frame(ticker="", volatility=1:20, geometric_return=1:20)
capm$ticker <- listings$Symbol[1:20]
for(i in 1:20) {
information_on_stock <- getcapm(capm$ticker[i])
capm$geometric_return[i] <- information_on_stock[1]
capm$volatility[i] <- information_on_stock[2]
}
main_name <- paste(market, " / ")
main_name <- paste(main_name, sector)
main_name <- paste(main_name, " in 2015")
plot(x=capm$volatility,y=capm$geometric_return,pch=19, main = main_name, xlab="Stock Volatility", ylab="Stock Return")
#I want to know which stock is outlier.
textxy(capm$volatility, capm$geometric_return, capm$ticker)
[Outcome]
(1) NASDAQ / Technology
Google, Apple didn't do well in 2015, and so did other firms, like Qualcomm. If I had drawn CAPM, it would have spit out negative beta.
Google, Apple didn't do well in 2015, and so did other firms, like Qualcomm. If I had drawn CAPM, it would have spit out negative beta.

(2) NASDAQ / Health care
Gilead (Ticker: GILD) did a good job, but it's lower than 2%. Other than Gilead, if you had invested in health care sector, it would have been a disaster.

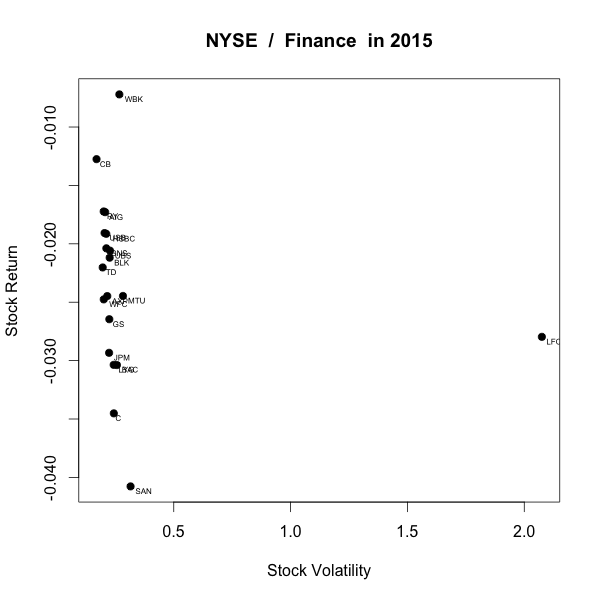
(3) NYSE / Finance
It was the weirdest risk-return graph that I've ever seen. I can see some outlier right over there (China Life Insurance Company, LFC) as the china market got volatile last year. On average, they didn't do well.
(4) NYSE / Technology
Only Palo Alto Networks (PANW) had a positive return. SAP didn't have a good time in 2015.

No comments:
Post a Comment